Join the community and learn how make content work with CELUM.


Sorry, we were not able to find a match
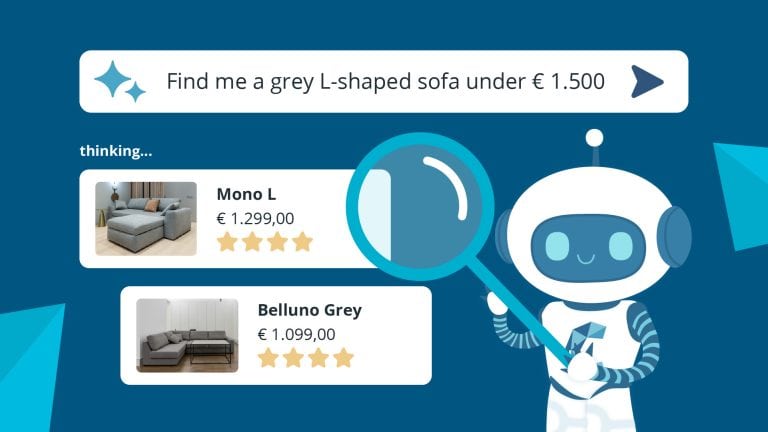
Unlock the power of your content today.
Simplify workflows, reduce errors, and spend more time with your team working on the next big thing.

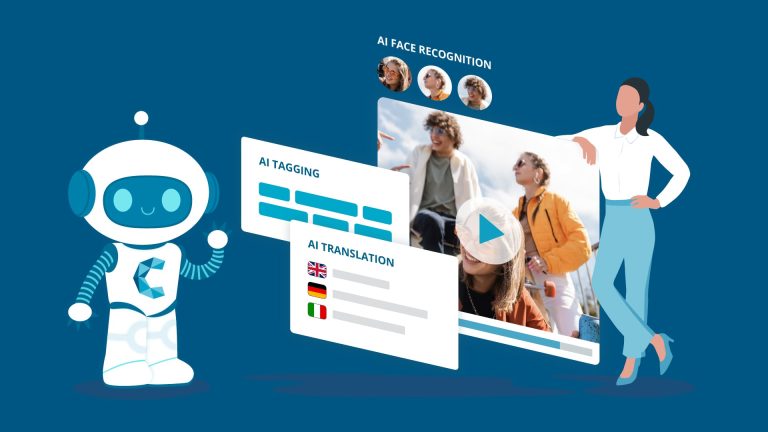
Streamlining content creation and management of assets, simplifying online proofing and collaboration, to facilitate a content exploration experience that wows your audiences.
A platform for global brands to manage their digital content, deliver omnichannel, personalised marketing strategies, and overcome complexity in product assets, audiences, integrations and more.
Specialised in mastering the complexity of assets, audiences, integrations and more.
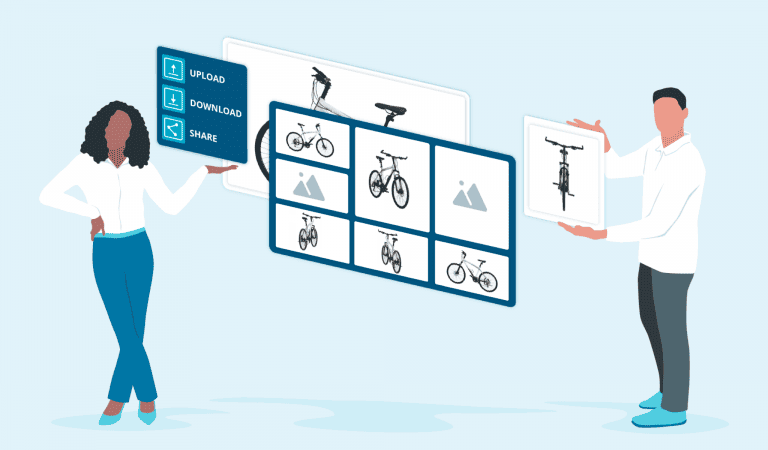
Centralise, connect, manage in bulk product assets.
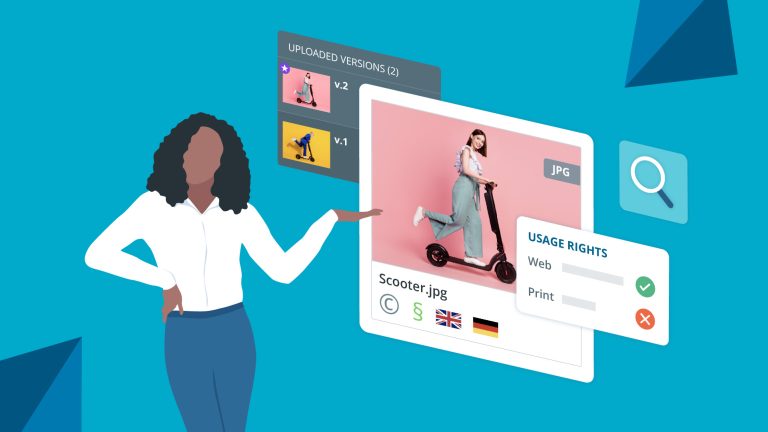
Give concise feedback. Create workflows. Collaborate efficiently.
100+ applications and extensions accessible via integrations.